Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Решение задачи 1, распознаваниеСодержание книги
Поиск на нашем сайте Наиболее простое решение состоит в том, чтобы посчитать вероятность появления последовательности наблюдений для каждой возможной последовательности состояний модели, а затем сложить эти вероятности. Пусть Q={Q1,Q2,…Qs}- множество всех возможных последовательностей состояний той же длины, что последовательность O. Их число будет равно S=Nτ -1, где N – число состояний, τ – длина последовательности. Пусть i-я последовательность Qi представляет ряд состояний {qi1,qi2,…,qiτ}. Тогда для i-й последовательности состояний вероятность появления последовательности наблюдений O равна:
Вероятность же появления самой i-й последовательности состояний равна
По определению скрытой Марковской модели вероятности наблюдения в каждом из состояний зависит только от самого состояния и не зависит от предыдущих состояний. Поэтому вероятность появления указанной последовательности наблюдений O для нашей модели можно рассчитать так:
Очевидно, что нам потребуется (2τ -1) Nτ умножений и Nτ -1 сложений, что уже для N=10 состояний и длины последовательности наблюдений τ=10 дает число вычислений, равное 19*1010+1010-1=2*1011-1. Это очень много. К счастью, существуют более эффективные алгоритмы решения этой задачи. Наиболее известны два – алгоритм прямого хода и алгоритм обратного хода.
Алгоритм прямого хода. Вводится переменная αt(i) – вероятность того, что к моменту времени t система будет находиться в i-м состоянии, а последовательность порожденных ею до этого момента наблюдений равна о1,о2,…,ot. Алгоритм следующий. 1 шаг. Для всех i от 1 до N α0(i)=πi bi(o1)
2 шаг. Для всех t от 1 до τ и для всех j от 1 до N
3 шаг.
Алгоритм обратного хода. Вводится переменная τt(i) – вероятность того, что к моменту времени t система будет находиться в i-м состоянии, а последовательность порожденных ею после этого наблюдений равна оt+1, оt+2,…oτ-1,oτ Алгоритм следующий. 1 шаг. Для всех i от 1 до N βτ(i)=1
2 шаг. Для всех t, идущих в обратном порядке от τ-1 до 1 и для всех i от 1 до N
3 шаг.
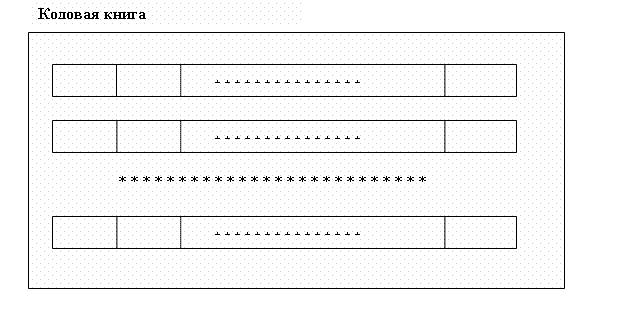
Для осуществления распознавания на основе скрытых моделей Маркова необходимо построить кодовую книгу, содержащую множество эталонных наборов для характерных признаков речи (например, коэффициентов линейного предсказания, распределения энергии по частотам и т.д.). Для этого записываются эталонные речевые фрагменты, разбиваются на элементарные составляющие (отрезки речи, в течении которых можно считать параметры речевого сигнала постоянными) и для каждого из них вычисляются значения характерных признаков. Одной элементарной составляющей будет соответствовать один набор признаков из множества наборов признаков словаря.
На рисунке каждая запись кодовой книги относится к одному набору, каждое поле записи – содержит значение одного признака. Построив кодовую книгу, мы должны настроить модель распознавания. Одна скрытая модель Маркова λ={A,B,π} ставится в соответствие некоторой распознаваемой единице речи, как правило, слову. Фрагмент речи разбивается на отрезки, в течении которых параметры речи можно считать постоянными. Для каждого отрезка вычисляются характерные признаки и подбирается запись кодовой книги с наиболее подходящими характеристиками. Номера этих записей и образуют последовательность наблюдений O={o1,o2,…oτ} для модели Маркова. Каждому слову словаря соответствует одна такая последовательность. Далее A – матрица вероятностей переходов из одного минимального отрезка речи (номера записи кодовой книги) в другой минимальный отрезок речи (номер записи кодовой книги). В – вероятности выпадения в каждом состоянии конкретного номера кодовой книги. В нашем случае?i=1 при i=0,?i=0 при i>0. На этапе настройки моделей Маркова мы применяем алгоритм Баума-Уэлча для имеющегося словаря и сопоставления каждому из его слов матрицы A и B. При распознавании мы разбиваем речь на отрезки, для каждого вычисляем набор номеров кодовой страницы и применяем алгоритм прямого или обратного хода для вычисления вероятности соответствия данного звукового фрагмента определенному слову словаря. Если вероятность превышает некоторое пороговое значение – слово считается распознанным.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
Последнее изменение этой страницы: 2022-09-03; просмотров: 120; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.150 (0.006 с.) |