Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Сегментация на основе кластеризацииСодержание книги
Поиск на нашем сайте Рассмотрим простейший случай сегментации. Пусть известно, что отрезок речи содержит две фонемы, начало речевого отрезка соответствует началу первой фонемы, окончание – концу второй фонемы. Т.е. задача сводится к определению момента времени, в который происходит смена фонем. В этом случае можно применить технику кластерного анализа, используемую для построения пофонемной кодовой книги. В ее основе лежит процедура усреднения. Поскольку заранее известно, что перед нами два участка, соответствующие двум различным классам, то критерием разделения двух звуков может быть изменение центроида, к которому тяготеют вектора признаков. Приведем пример получения сегментации слога. Наговариваем слог, состоящий из двух фонем, например, слог “си” и строим кодовую книгу из двух кодовых векторов. С микрофона вводится речевой сигнал. Машина разбивает сигнал на отрезки по 368 отсчетов и для каждого из них строит вектор признаков. При сигнале в 10 тысяч отсчетов таких векторов получается 27. Далее происходит разбиение векторов на классы и построение соответствующих кодовых векторов. Пусть речевой сигнал задается множеством векторов
Выберем число
Определим теперь функцию
Если наименьшее значение этой функции достигается при Амплитудная сегментация Следующий метод сегментации является по сути своей амплитудным. Сигнал в 10 тысяч отсчетов разбивается на отрезки по 300 отсчетов в каждом. Для каждого из них вычисляется величина
Здесь
Наконец, весь сигнал разбивается на участки, состоящие из отрезков, для которых pi < p и участки, состоящие из отрезков, для которых pi ≥ p. Границы между этими участками принимаются за искомые границы сегментации. Этот метод с высокой надежностью позволяет выделить участки отвечающие звукам “с”, “ш”, “щ”, “ц”, “ч”, “ф”, “х”, “б”, “г”, “д”, “п”, “к”, “т”. Он может выделять также другие согласные, особенно при отсутствии в слове вышеперечисленных звуков. В целом этот простой, надежный и чрезвычайно быстро работающий метод может, как показывает опыт, с успехом служить для целей предварительной сегментации речевого сигнала.
|
||||||||||||
|
|
Последнее изменение этой страницы: 2022-09-03; просмотров: 147; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.192 (0.009 с.) |

 .
.
 и построим вектора
и построим вектора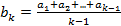 ,
,  .
.

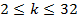 .
.
 то правый конец отрезка с номером
то правый конец отрезка с номером 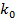 принимается за границу аллофона. Далее отрезки по одну сторону найденной границы отбрасываются, к оставшейся части сигнала применяется вышеописанная процедура и т.д. Этот метод позволяет весьма надежно разделять две соседние гласные фонемы или гласную и соседствующую с ней сонорную согласную.
принимается за границу аллофона. Далее отрезки по одну сторону найденной границы отбрасываются, к оставшейся части сигнала применяется вышеописанная процедура и т.д. Этот метод позволяет весьма надежно разделять две соседние гласные фонемы или гласную и соседствующую с ней сонорную согласную. .
.
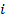 - номер отрезка
- номер отрезка  ,
,  - значение сигнала на
- значение сигнала на 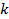 -ом отсчете
-ом отсчете  , как известно, принимают целочисленные значения от 1 до 256, так что под знаком суммы стоят отклонения от средней линии. Затем вычисляется среднее величин
, как известно, принимают целочисленные значения от 1 до 256, так что под знаком суммы стоят отклонения от средней линии. Затем вычисляется среднее величин  :
: .
.