Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
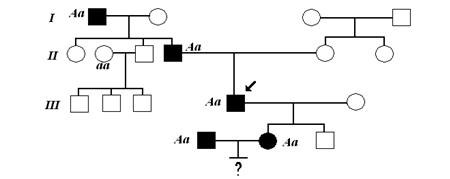
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Structure of the knowledge baseПоиск на нашем сайте Structure of the knowledge base Knowledge base of ESTHER system consists of 19 knowledge bases for the decision classes (different classes of poisonings) and 12 knowledge bases for differential diagnostics. After the construction of complete and noncontradictory knowledge base, methods of questionnaire theory [6] have been used to produce an optimal decision tree for each class of medicines. Criterion of optimality here is a minimum average number of questions needed to arrive to a conclusion about the existence and severity of poisoning by the drug of this class [7]. Decision tree presents a strategy of putting questions about values of clinical signs with the goal to ascertain the fact of intoxication and state of a patient. Each node of the tree is a question about a value of a diagnostic sign. Depending on the answer the following node is chosen. One of the decision trees embedded into the ESTHER knowledge base is presented on Fig 1.
Fig. 1.The constructed optimal decision tree for diagnosing of poisoning by one of the medicines.
System architecture Principal modules of ESTHER system and their interactions are represented at the diagram (see Fig.2).
There are two basic modes of a user’s work with ESTHER system – data input mode and consultation mode. In the data input mode a user sees a list of clinical signs grouped under the titles: “External examination data”, “Anamnesis”, “Cardiovascular system”, etc. All information about a patient including his/her state, illness history, complaints and so on is stored in the “Case Box” module.
“Hypotheses Advancement” module monitors this information and makes suppositions about a possible poisoning cause. If there are several concurrent hypotheses it selects one that is supported by the largest number of typical signs’ values. When a hypothesis for checking is formed, it is transferred to the “Hypotheses Checking” module when system is in the consultation mode. In the consultation mode the system successively checks and puts forward new hypotheses. While checking a hypothesis about a poisoning by some drug, the system uses the constructed optimal decision trees. A pass through the tree is accomplished and at the nodes, where values of clinical signs are still unknown, a user is questioned about values of appropriate signs to reach a conclusion. As a result of this pass one of the following conclusions is drawn: “Serious poisoning by medicine A”, “Mild poisoning by medicine A” or “No poisoning by medicine A”. The last means that either the poisoning was caused by the medicine other than X or there is no drug poisoning at all. In general case it may happen as a result of hypotheses checking that several hypotheses about poisonings by different medicines are confirmed. This may be the case if patient actually has taken several medicines as well as when different medicines result in similar clinical pattern. In order to refine the diagnosis the “Differential Diagnostics” module is applied. An oriented graph is constructed in the “Differential Diagnosis” module. Nodes of the graph correspond to confirmed hypotheses and arcs correspond to the relations of poisonings’ probabilities between different medicines. For example, if differential diagnostics rules state that poisoning by medicine A is more probable than poisoning by medicine B, then nodes A and B in the graph are connected by the arc, which originates at node A and enters node B. After that, the graph is condensed, that is a kernel of undominated nodes is extracted. For each node A belonging to the kernel the string “Poisoning by medicine A is most probable” is written to the final diagnosis (module “Diagnosis”). For the other nodes B the string “Poisoning by medicine B is not excluded” is written to the diagnosis. Our discussion with expert revealed that these two wordings are sufficient for practical purposes and there is no need in more precise distinguishing among poisonings’ probabilities. There is also the module of recommendations on treatment as a constituent part of the ESTHER system (“Treatment” on the diagram). It can be used as a reference manual for getting acquainted with basic methods of treatment of poisonings by one or another medicine. Another, more important feature is its ability to give recommendations on the particular given case of poisoning. Using a diagnosis made by other modules of the system and extracting clinical pattern of poisoning from the “Case Box” module it is able to recommend treatment with regard to the gravity of poisoning, degree of damage to the systems of human organism. It can also prescribe a symptomatic therapy. Moreover, when prescribing treatment methods and dosage of antidote medicines it is possible to take into account age, weight and illness history of the patient. Conclusion From our point of view the ability of expert system to behave like a human is the critical factor for its application. The developed ESTHER system includes large knowledge base that closely imitates expert knowledge and reasoning in the problem of drug poisonings diagnostics. It is important to note that the open architecture of ESTHER provides a possibility to add new decision classes (causes of intoxications) and new diagnostic signs for such classes. A revision of individual knowledge bases is also possible for any decision class using knowledge of a more experienced (for this class of poisonings) physician. The expert system for the diagnostics of acute drug poisonings is the example of “knowledge distribution” for large groups of specialists. We believe that appearance of new diseases and new drugs make the problem of “knowledge distribution” for large areas more important.
References 1. Pople, H.E. : The Formation of Composite Hypotheses in Diagnostic Problem Solving: An Exercise in Synthetic Reasoning, The Fifth International Joint Conference on Artificial Intelligence, Boston, MIT, 1977. 2. Shortliffe, E.H.: Computer-based Medical Consultations: MYCIN, New York, American Elsevier, 1976. 3. Larichev, O.I., Mechitov, A.I., Moshkovich, H.M., Furems E.M.: The Elicitation of Expert Knowledge, Nauka, Moscow, 1989 (in Russian). 4. Larichev, O.I., Moshkovich, H.M., Furems, E.M., Mechitov, A.I., Morgoev, V.K.: Knowledge Acquisition for the Construction of the Full and Contradictions Free Knowledge Bases, IEC ProGAMMA, Groningen, The Netherlands, 1991. 5. Larichev, O.I., Bolotov, A.A.: The DIFKLASS System: Construction of Complete and Noncontradictory Expert Knowledge Bases in Problems of Differential Classification, Automatic Documentation and Mathematical Linguistics, Vol. 30, N. 5, Allerton Press, New York, 1996. 6. Parhomenko, P.P.: The Questionnaires Theory: Review, Automatics and Telemechanics, N. 4, Moscow, 1970.(in Russian) 7. Naryzhnyi, E.V.: Construction of the Optimum Questioning Strategy for a Complete Expert Data Base, Automatic Documentation and Mathematical Linguistics, Vol. 30, N. 5, Allerton Press, New York, 1996.
|
||
|
|
Последнее изменение этой страницы: 2024-07-06; просмотров: 76; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.147 (0.006 с.) |