Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Analysis of game space strategies usingСодержание книги Поиск на нашем сайте ANALYSIS OF GAME SPACE STRATEGIES USING NEURAL NETWORKS Rimma A. Tomakova1, Vadim V. Dzhabrailov, Maxim V. Tomakov1, Dmitry K. Reutov1 1Southwest State University, 94, 50 Let Oktyabrya str., Kursk, 305040, Russian Federation E-mail: rtomakova@mail.ru Abstract
The purpose of the research is to develop methods for improving the efficiency of neural networks for building artificial intelligence systems in the analysis of game space. Methods.The main method used in the developed software solution is the method of deep learning of neural networks with reinforcement based on the model of proximal optimization of the strategy. Results. It is shown that the increase in the efficiency of neural networks for the subsequent training of artificial intelligence is achieved, firstly, by using convolutional neural networks, and secondly, by expanding the functionality, by selecting the reference point of the formula. Conclusion.The development of a software product for analyzing game strategy using neural networks will help to analyze the actions of players, which automatically determines their behavior, aimed at studying the individual characteristics of the game space. Keywords: neural networks, artificial intelligence, ML-Agents, reinforcement learning, strategy optimization, learning agents, academy, learning environment, Unity.
Введение.В настоящее время разработано большое количество видов нейронных сетей, которые ранее не использовались в игровых приложениях [1, 2, 3]. На сегодняшний день наиболее успешным примером применения нейронных сетей в видеоиграх является искусственный интеллект (ИИ) OpenAI Five, который используется для анализа поведения виртуальных соперников в видеоиграх [4, 8]. Нейронные сети, составляющие основу искусственного интеллекта в OpenAI Five, обучены применительно к 18 игрокам из 119, принимающих участие в этой игре. Однако и при таких ограничениях ИИ успешно побеждает разнообразные команды реальных соперников, принимающих участие в игре. Обучение нейронных сетей, предназначенных для последующего их использования в видеоиграх, сопряжено с рядом возникающих проблем. Эти проблемы обусловлены тем, что видеоигровая среда достаточно динамична и нетривиальна для обучения нейронной сети и один участник игры во время проведения геймплея не способен нагенерировать необходимый объем информативных признаков о тактике поведения, достаточный для обучения нейронной сети. В тоже время модели ИИ, применяемые для ведения бизнеса или в симуляторах для автопилотов дают возможность принимать решения в условиях четко установленных ограничений и правил, в отличие от видеоигровых. Специфика решения такого рода задач также состоит в необходимости обучения алгоритмов обработки информации в условиях малых объемов выборок информативных признаков, поскольку во многих случаях сбор и обработка дополнительных обучающих данных существенно затруднены, либо невозможны. В связи с этим возникает актуальная задача разработки новых алгоритмов и методов, предназначенных для повышения качества обучения нейронных сетей при малом объеме исходных обучающих данных, а также разработки универсальных методов искусственного размножения информативных признаков [5, 6, 7]. Подобные алгоритмы могут быть применены для решения широкого класса задач, возникающих на практике. В настоящее время для решения проблемы обучения алгоритмов с использованием обучающих выборок ограниченного объема в [5, 6, 7] применяют методы генерации и искусственного размножения данных с использованием стандартных и смешанных непараметрических оценок плотности распределения. Для прогнозирования состояния поведения игроков в видеоиграх могут быть использованы гибридные модули с виртуальными потоками, которые отражают скрытые системные связи между полученными в результате проведения игры данными и виртуальными данными. С этой целью в формируемые виртуальные потоки целесообразно вводить дополнительные информативные признаки, которые несут информацию о скрытых связях между исходными признаками [8, 9]. Скрытые связи определяются аппроксимирующей функцией, построенной по данным, извлеченным из обучающей выборки, на основе вероятностного программирования [10, 11]. Возможная архитектура нейронной сети с виртуальным потоком представлена на рисунке 1.
Рис. 1. Архитектура нейронной сети с виртуальными потоками, предназначенная для генерирования данных
Fig.1. The architecture of a neural network with virtual threads, designed to generate data
При разработке процедур проведения игр следует учитывать большое разнообразие участников, каждый их которых обладает различными личностными предпочтениями, темпераментом, манерой ведения игрового процесса, использованием возможностей, которые предоставляет геймплей в игровом приложении [12, 13]. При этом участники с одинаковым игровым опытом и навыком, часто используют различные неординарные и сложные игровые приемы, сосредотачивают свое внимание на разнообразных элементах и возможных подходах к геймплею. В этом заключается основная проблема, состоящая в оптимальном формировании игрового пространства и процедур ведения игры с целью организации высокой заинтересованности и наибольшего одновременного привлечения участников игры. Для решения этой проблемы формируются задачи исследований, включающие создание разработчиками стандартов сложности, позволяющие участникам игрового процесса выбирать и анализировать предоставляемые возможные уровни сложностей с учетом личностных ориентиров. Процесс индивидуализации игрового пространства с использованием нейронных сетей может быть простроен значительно более гибко. На основе нейронных сетей различной архитектуры появляется возможность установления статистических характеристик и вероятностей выбора решений, агрегирования и кластеризации накопленной информации, полученной в процессе проведения игры такой как: - характеристика психологических особенностей индивида (его миролюбивости, импульсивности, агрессивности, уравновешенности и т.д.); - время реакции игрока на изменение ситуации в игровом пространстве; - наиболее часто применяемые критерии выбора решений. Сбор и анализ информации на основании нейронных сетей дает возможность мгновенно менять соответствующие характеристики противников, а также позиции игрового окружения с целью привлечения заинтересованности в процессе ведения игры [9, 10, 11]. Значительная часть игр, используемая в настоящее время, предусматривает возможность выделения небольших ресурсов, приблизительно от 1 до 5% ресурсов процессора, на применение искусственного интеллекта, что существенно тормозит внедрение новых технологий с применением нейронных сетей. Объект исследования. В качестве объекта исследования использовался специальный плагин ML-Agents, предназначенный для игрового движка Unity, позволяющий создавать новые или использовать готовые среды для обучения агентов [12, 13, 14, 15, 16]. Плагин состоит из трех компонентов, показанных на рисунке 2.
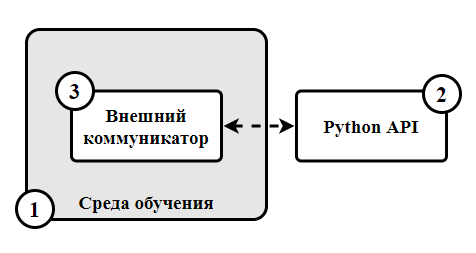
Рис.2. Схема взаимодействия среды обучения с Python API Fig.2. Diagram of interaction between the learning environment and the Python API
Первый блок представляет среду обучения (Learning Environment), которая содержит элементы среды и сцену из Unity. Второй блок содержит Python API, в котором расположены алгоритмы обучения с подкреплением, например, Proximal Policy Optimization и Soft Actor-Critic. Python API используется для запуска, обучения, тестирования и сохранения с выводом результатов. Третий блок представляется как внешний коммуникатор, который связывает Python API со средой обучения. При этом среда обучения состоит из компонентов, продемонстрированных на рисунке 3.
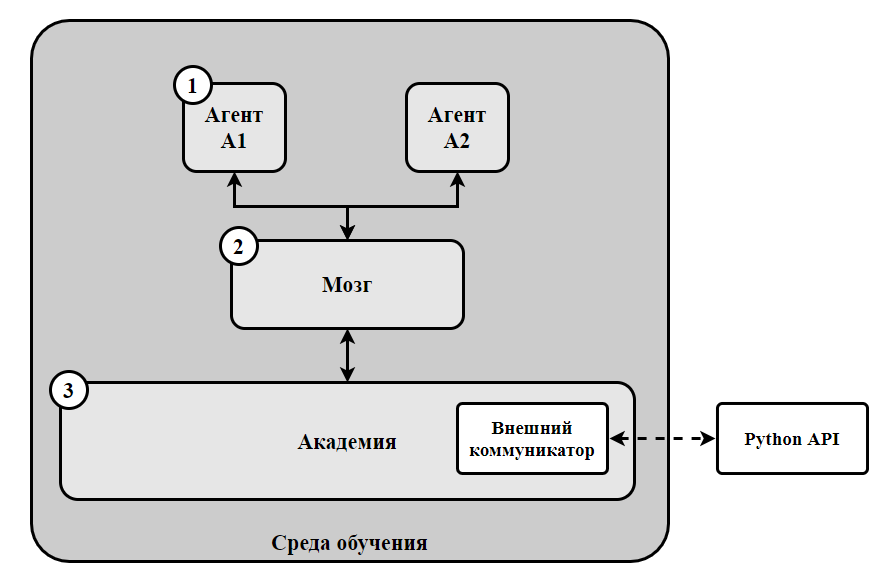
Рис.3. Схема компонентов ML-Agents Fig.3. ML-Agents Component Diagram
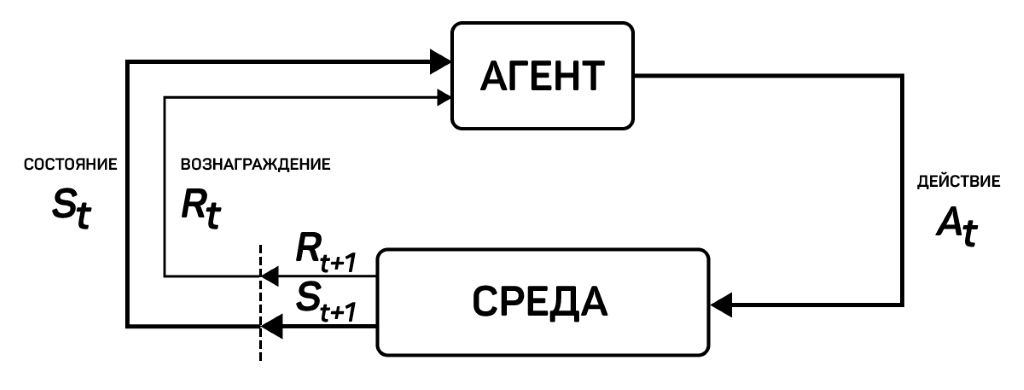
Первый компонент представляется как Агент (Agent) – актер сцены, которого необходимо тренировать. Вторым компонентом выступает блок «Мозг» (Brain) – в него записываются и хранятся всевозможные воздействия, которые следует выполнять в каждом из возможных состояний объекта. Третий компонент – «Академия» (Academy) предназначен для процессов обработки запросов от системы Pyton API, посылаемых через внешний коммуникатор. Этот компонент выполняет функции управления агентами на сцене, а также процессом принятия решений, посылаемых через мозг агента. Для достижения поставленных целей требуется воспользоваться процессом RL (Reinforcement Learning или обучение с подкреплением) [16, 17, 18, 19]. Его функционирование можно представить в виде цикла, представленного на рисунке 4.
Рис.4. Схема работы цикла процесса RL Fig. 4. Scheme of the RL process cycle operation
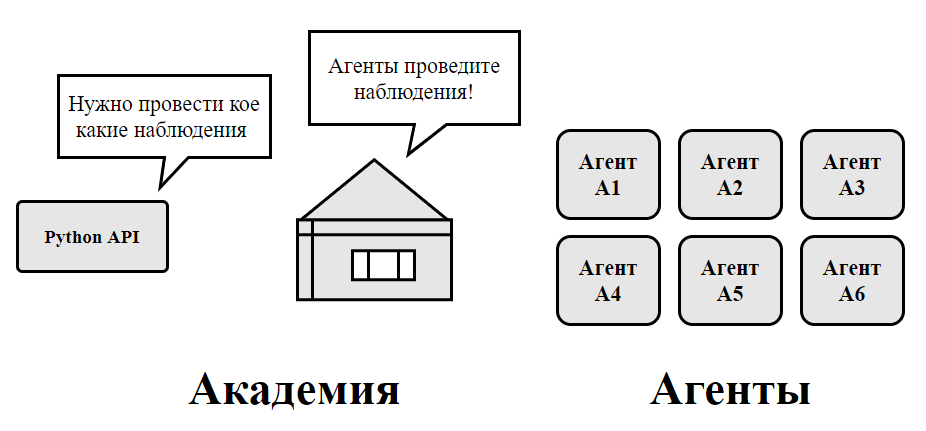
В том случае, если предположить, что агенту хотелось бы научиться играть в платформер, то процесс RL при этом будет содержать: - агент попадет в новое состояние S0 из внешней среды, возникающей в первом кадре планируемого платформера; - руководствуясь текущим состоянием S0, агент выполняет произвольное действие A0, затем перемещается вправо; - вследствие выполненных действий среда переходит из состояния S0 в новое состояние S1; - за каждый произведенный шаг агент приобретает награду R1, при этом успех оценивается +1, а неудача -1. Награду получает агент в том случае, если он смог добраться до окончания уровня. Данный цикл обучения с подкреплением формирует порядок состояний, действий и награды, используемые для обучения. Цель агента заключается в максимизации ожидаемой суммы наград, полученных при выполнении цикла обучения. На рисунке 5 представлены взаимодействия элементов среды обучения. Рис. 5. Описание работы среды обучения Fig. 5. Description of the learning environment
Следовательно, Академия обеспечивает синхронизацию между агентами и посылает им установки, при этом выполняются процедуры: - сбор наблюдений в процессе; - подбор действий, в зависимости от заложенных инструкций; - свершение действия и его завершение; - анализ действия – если число шагов исчерпывается или цель достигается, то происходит сброс. Материалы и методы исследования.В основе программного обеспечения для анализа игровой стратегии лежат общие методы и материалы о нейронных сетях и возможностях их применения. Метод обучения с подкреплением применяется в плагине ML-Agents от компании Unity, для данного способа применяется модель проксимальной оптимизации стратегии (PPO) [19]. PPO применяет нейронную сеть для аппроксимации идеальной функции, что сравнивает наблюдения агента с наилучшими результатами его действий, которыми агент мог бы заняться в текущем состоянии [4, 16, 17]. Алгоритм проксимальной оптимизации стратегии в плагине ML-Agents реализован через программную библиотеку для машинного обучения Tensor Flow от компании Google и выполняется в отдельном процессе Python API, который взаимодействует с запущенной сценой Unity посредством внешнего коммуникатора. Результаты и их обсуждения.В результате проведенных исследований было разработано программное изделие для анализа игровой стратегии с использованием нейронных сетей. На первом этапе исследования решалась задача об установлении возможностей обучения искусственной нейроннойсети реагировать на объекты в игровых пространствах. Для этого исследователю потребуется сначала оценить сложность существующих уровней, оценить их в виде весовых коэффициентов. При создании игровых пространств, искусственный интеллект дает возможность организовывать для каждого пользователя свои личные уровни, подходящие его приоритетам, игровому опыту и навыку, для того, чтобы предоставить ему гарантированный интересный видеоигровой процесс. В качестве единицы игрового пространства выступает представляемая самодостаточная комната. Схожее возможно приметить в играх жанра «рогалики», такие как, например, The Binding of Isaac. Искусственный интеллект будет рекомендовать игроку новое игровое пространство с подходящей сложностью, зависящей от методов ведения игры, поведения индивида и сложности текущего уровня [2, 18, 19]. Сложность уровней каждого игрового пространства устанавливается на основании алгоритма, оценивающим соперников и предметов на текущем уровне, которая продемонстрирована на рисунке 6.
Рис.6. Сложности уровней, рекомендуемые в последовательности уровней Fig.6. Difficulty levels recommended in the sequence of levels
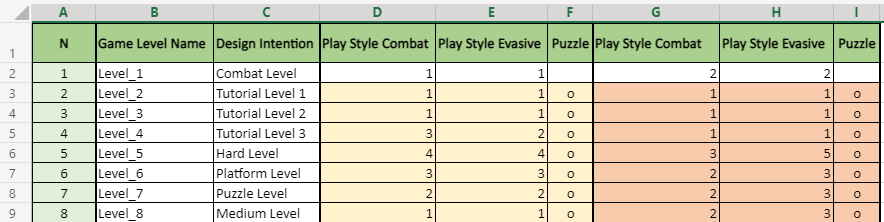
Наиболее простым шагом в процессе оценки является установление численных значений для соперников или выявления их радиуса и дальности зрения. Значительно сложнее оценивать отыскивающиеся в комнате интерактивные объекты для взаимодействия с игроком (ключи и коллекционные объекты). Именно поэтому целесообразно использовать воспользуемся искусственную нейронную сеть, заменив такой эвристический алгоритм. Для обучения искусственного интеллекта, потребуется необходимые сведения [19]. Для систематизации игрового пространства по сложности, потребуется единица информации, которая представима в виде пары «уровень-сложность». На рисунке 7 приведены возможные оценки сложности уровней. Следует заметить, что анализ состояний любого пространства на основе алгоритма не сможет постоянно формировать множество разумных результатов. Причина заключается в том, что формируемое множество результатов ограничено сверху, поскольку это предусмотрено самим алгоритмом. С этой целью потребуется предварительно создать геймплейного бота, способствующего успешному прохождению возникающих уровней и позволяющему оценивать сложность игрового пространства по полученным результатам. Однако при этом нельзя повысить скорость игрового процесса до значений, подходящих для обучения. Потому понадобится отказаться от данной идеи и вначале делать прохождение человеком.
Fig. 7. An example of assessing the difficulty of levels
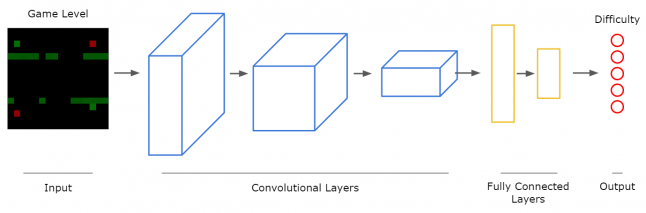
Как только разметка данных по игровым пространствам будет завершена, понадобится совершить скриншоты экрана сцен Unity с игровым пространством в редакторе, которые далее впоследствии станут версией нового уровня. При этом учитывается, что обучение агента будет проходить с помощью набора предоставленных данных в виде пар «снимок игрового пространства - сложность». Для этого применяются снимки сцен с уровнями, поскольку они в низком разрешении более различимы, нежели скриншоты в высоком разрешении, другими словами, производительнее с позиции скорости обучения искусственного интеллекта и в качестве поступающих данных для результатов. Для успешного достижения желаемого результата процесса игры целесообразно использовать сверточные нейронные сети (Сonvolutional neural network, CNN), поскольку они лучшеподходят для классификации различных типов изображений (рис.8). Для оценки возможностей работы этой нейронной сети понадобится выбрать опорную точку, которая выведена заранее. Применение сверточных нейронных сетей позволило получить следующие результаты: - прогнозирование сложности, основанные на формуле повысили точность на 42%; - прогнозирование сложности, основанные на снимках сцен с уровнями из редактора Unity повысила точность на 62%. При применении обычной модели CNN при прогнозировании сложности, основанных на снимках точность увеличилась до 20%. Даже при использовании прочих сложных моделей CNN, результат сильно не изменился. На результаты отрицательно воздействует лишь возможность небольшого количества данных (всего около 1000 пар).
Fig. 8. Forecasting via CNN
Выводы.В результате выполнения данного исследования было разработано программное изделие для анализа игровой стратегии. С помощью данного приложения были исследованы разные подходы и методы оптимизации обучения нейронной сети при анализе игрового пространства и поведения игрока в нем. Таким образом, данное исследование продемонстрировало повышение эффективности обучения искусственного интеллекта с помощью метода глубинного обучения с подкреплением, а также смены нейронной сети на сверточный вариант который используется в плагине ML-Agents от компании Unity. В дальнейшем он может быть дополнен и расширен новыми моделями и подходами к обучению. Эти факты являются безусловными достоинствами применения данного подхода.
|
||
|
|
Последнее изменение этой страницы: 2024-06-17; просмотров: 64; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.216.150 (0.007 с.) |