Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Статистическая значимость (p-уровень) – вероятность получить результат о наличии связи, когда в генеральной совокупности связи нет (верна H0), т.е. полученная связь носит случайный характерСодержание книги
Поиск на нашем сайте Уровень значимости – это вероятность того, что мы сочли различия существенными, а они на самом деле не случайны. p-уровень значимости – количественная оценка надежности связи: чем меньше p, тем надежнее связь (значимость выше) Когда мы указываем, что различия достоверны на 5%-ом уровне значимости, или при р≤0,05, то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,05. Когда мы указываем, что различия достоверны на 1%-ом уровне значимости, или при р≤0,01, то мы имеем в виду, что вероятность того, что они все-таки недостоверны, составляет 0,01. напр., проверка гипотезы про память дала результат p = 0,05; это означает, что вероятность случайного различия уровня памяти мальчиков и девочек не превышает 5% ⇨ Уровень значимости – это вероятность отклонения нулевой гипотезы, в то время как она верна Что определяет уровень значимости (p)? Значимость тем выше (p меньше), чем: • больше величина связи; • больше объем выборки; • меньше изменчивость признака. NB: чем больше гипотез проверяется на одной выборке, тем выше вероятность получить случайный результат • напр., если при p < 0,05 проверяется 20 гипотез (напр., корреляция), то одна из гипотез наверняка подтвердится Принято (в психологии) использовать несколько критических значений p-уровня
35. Интерпретация статистических решений. Основные принципы. Статистический вывод.
Модель статистического вывода – оценка значимости (истинности) проверяемой гипотезы в рамках выбранной описательной модели Статистический вывод (statistical inference) представляет собой процесс получения логических выводов о статистической совокупности на основании случайно извлеченных выборок. Логика статистического вывода не зависит от конкретной проблемы и используемых статистических методов. На основании выборки исследователь тестирует те или иные гипотезы, часто: · о различии статистических совокупностей,
Проверка этих статистических гипотез может быть уложена в следующую последовательность этапов статистического вывода: · Формируется нулевая и альтернативная гипотезы. Например, нулевая гипотеза (Ho): параметр совокупности равен какому-то определённому значению, альтернативная теория (Ha): не равен. Обычно исследовательская теория является альтернативной к уже существующей парадигме. Чаще всего мы хотим указать на имеющую место новую закономерность (альтернативная гипотеза) и соотнести ее с консервативной нулевой гипотезой (которая часто говорит о случайной природе находок и об отсутствии закономерностей в реальности). · Формируется случайная выборка элементов совокупности и определяются параметры выборки. · Преобразуется параметр выборки в статистический критерий. · Находим p-значение для полученного статистического критерия. · Сравниваем с критическим значением статистического критерия. · Делаем выводы о сохранении нулевой гипотезы или о подтверждении альтернативной. Нулевая гипотеза сохраняется или отвергается исходя из того, насколько вероятным оказывается наблюдаемый результат. Для оценки выборочных статистик в отношении изменчивости используются статистические критерии, для которых имеются рассчитанные распределения и по которым эти самые вероятности можно посчитать (z-, хи-квадрат-, t-, и прочие виды распределений). Если различие между исследуемыми группами (выборками) заметно выражено относительно величины изменчивости данных, исследователь отвергает нулевую гипотезу и делает вывод, что случайное появление такого результата маловероятно: полученный результат статистически значим. Обобщение и интерпретация статистической информации - проводится анализ статистической информации на основе применения обобщающих статистических показателей: абсолютных, относительных и средних величин, вариации, тесноты связи и скорости изменения социально-экономических явлений во времени, индексов и др. проведение анализа позволяет проверить причинно-следственные связи изучаемых явлений и процессов, определить влияние и взаимодействие различных факторов, оценить эффективность принимаемых управленческих решений, возможные экономические и социальные последствия складывающихся ситуаций. Основные принципы:
36. Проблема статистического вывода в психолого-педагогическом исследовании. Статистические выводы используются для обобщения данных из выборки в отношении всей генеральной совокупности. Случайные ошибки, характерные для выборочного исследования, могут привести к тому, что выборка не будет [достаточно точной] моделью генеральной совокупности. В действительности выборка никогда не является моделью генеральной совокупности на все 100%, а лишь ее более или менее искаженным вариантом. Для того, чтобы оценить такие искажения и, следовательно, сделать более точные выводы о генеральной совокупности и используются статистические выводы. Прежде всего, они позволяют оценить вероятность того, что выявленные в выборке взаимосвязи, различия, величины и т.д. характерны исключительно для выборки, но не для генеральной совокупности. Логика здесь следующая: если такая вероятность высока, то принимается решение, согласно которому параметры выборки не характерны для генеральной совокупности и наоборот – если такая вероятность низка, то принято считать, что соответствующие параметры выборки говорят о параметрах генеральной совокупности. Важно помнить – достижение 100% гарантии того, что результаты, полученные в исследовании, характерны для генеральной совокупности, возможно лишь в том случае, когда проведено сплошное исследование, т.е. опрос всех представителей генеральной совокупности. Но это уже не выборочное исследование и оно не предполагает использование статистических выводов. В самом общем виде статистические выводы можно разделить на две группы: 1) интервальное оценивание (построение интервала, в который с заданной вероятностью должно попасть среднее значение либо пропорция генеральной совокупности); 2) проверка статистических гипотез (вероятностный вывод о том, что определенные параметры выборочной совокупности отображают (или же нет) параметры генеральной совокупности).
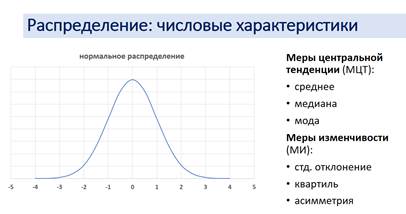
37. Описательные статистики и представление результатов исследования. Первичная обработка данных: описательные статистики (источник презентация) Первый шаг в обработке данных (второй – после проверки на ошибки, выбросы и пропуски) – оценка свойств распределения количественных переменных Тесно связана с представлением данных Цель – продемонстрировать характер данных, описание их в обобщенной форме Обычно используется при описании выборки и основных переменных Выделяют 2 группы описательных статистик: · Меры центральной тенденции · Меры изменчивости
Меры центральной тенденции отражают наиболее типичное значение выборки (распределения) Среднее – основная мера центральной тенденции. Применима лишь к метрическим данным (интервальным, отношений). Удобно для интерпретации нормального (симметричного) распределения. (источник сеть) Количественные (метрические) данные являются непрерывными по своей структуре. Эти данные либо измерены с помощью интервальной шкалы (числовая шкала, количественно равные промежутки которой отображают равные промежутки между значениями измеряемых характеристик) Категориальные (неметрические) данные – это качественные данные с ограниченным числом уникальных значений и категорий. Существует два вида категориальных данных: номинальные – используется для нумерации объектов и порядковые – данные, для которых существует естественный порядок категорий. (источник презентация)! Грубая ошибка – среднее для номинативных переменных. Примеры номинальных переменных включают регион, почтовый индекс или религию. Медиана – делит распределенные данные пополам. Может выступать альтернативой среднему, когда она не симметрично или использованы порядковые переменные. Мода – наиболее часто встречающееся значение. Это единственная МЦТ для номинальных данных (модальная категория – та градация, которая встречается чаще всего). Нередко может встречаться несколько мод.
|
|||||||||||||||||
|
|
Последнее изменение этой страницы: 2021-05-27; просмотров: 438; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.86 (0.006 с.) |