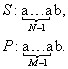Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Алгоритм прямого поиска подстроки в строкеСодержание книги
Поиск на нашем сайте
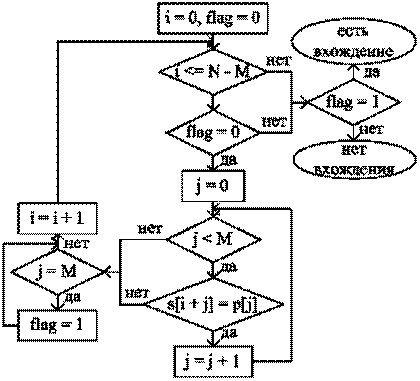
Алгоритм: 1. Установить i на начало строки S, т.е. i = 0. 2. Проверить, не вышло ли i + M за границу N строки S. Если да, то алгоритм завершен (вхождения нет). 3. Начиная с i -го символа s, провести посимвольное сравнение строк S и p, т. е. S [i] и P, S [i+1] и P,…, S [ i + M – 1] и P [ M – 1]. 4. Если хотя бы одна пара символов не совпала, то увеличить i и повторить шаг 2, иначе алгоритм завершен (вхождение найдено). Приведем две блок-схемы, описывающие алгоритм. В первой блок-схеме (рис.1) используется дополнительная переменная flag, которая явно изменяет свое значение с 0 на 1 при обнаружении вхождения образца P в текст S.
Рис. 1. Блок-схема: Алгоритм прямого поиска подстроки в строке
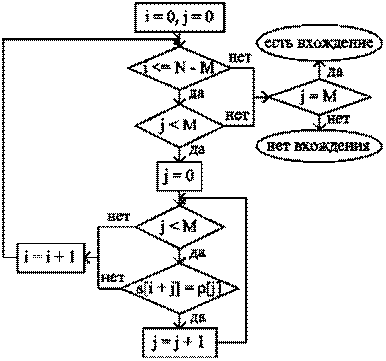
Во второй блок-схеме (рис.2) используется тот факт, что при j = M мы дошли до конца образца P, тем самым обнаружив его вхождение в строку S.
Рис. 2. Блок-схема: Алгоритм прямого поиска подстроки в строке
Пример 1: Строка S: на дворе трава, на траве дрова; подстрока P: траве. Реализация алгоритма поэтапно показана на рис.3.
Рис.3. Работа алгоритма прямого поиска подстроки в строке для примера 1 Алгоритм работает достаточно эффективно, если при сравнении образца P с фрагментом текста S довольно быстро выявляется несовпадение (после нескольких сравнений во внутреннем цикле). Это случается довольно часто, но в худшем случае (когда в строке часто встречаются фрагменты, во многих символах совпадающие с образцом) производительность алгоритма значительно падает. Пример 2: S: учить, учиться, учитель P: учитель
Рис.4. Работа алгоритма прямого поиска подстроки в строке для примера 2 6.4.2. БМ-поиск (Боуера–Мура)
Рассмотрим самый «плохой» для линейного поиска случай:
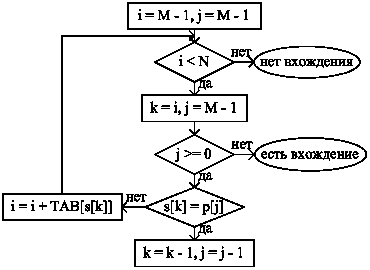
Подсчитаем для него число сравнений. Так как несовпадение символов происходит на последней букве образца, в каждом внешнем цикле производится M сравнений. Так как образец находится в конце строки, число внешних циклов равно N – M + 1, т.е. общее число сравнений есть M (N – M + 1). В 1975 году Р. Боуер и Д. Мур предложили алгоритм, который значительно ускоряет обработку данного случая. Алгоритм носит название БМ-поиска. В отличие от линейного поиска, сравнение в БМ-поиске начинается не с начала, а с конца образца P. Кроме того, образец предварительно анализируется и благодаря этому он сдвигается не на один символ, а в общем случае на несколько.
Рис.5. Блок-схема БМ-поиска
Рассмотрим механизм сдвига на примере. S: на дворе трава, на траве дрова P: дрова Начинаем сравнение с последнего символа образца. Символы, подвергшиеся сравнению, выделены: в строке – красным цветом, в образце – синим. Индекс k указывает на первый сравниваемый символ в строке S (первоначально k = M - 1), индексы i и j – на сравниваемые символы в образце и строке соответственно. Сначала i = M - 1, j = k, затем i и j уменьшаются на единицу, пока не произойдет несовпадение символов S [ j ] и P [ i ] либо не закончится образец (i = -1).
Совпадения не произошло при первом же сравнении, необходимо сдвинуть образец, т.е. увеличить индекс k. В БМ-поиске образец сдвигается так, чтобы «под» символом S [ k ] (в таблице) оказался совпадающий с ним ближайший к концу символ образца (иначе при j = k совпадение S [ j ] и P [ i ] точно не произойдет). Значит, в данном случае сдвигаем образец на одну позицию вправо, т.е. увеличиваем индекс k на единицу.
Совпадения образца со строкой опять не произошло, сдвигаем образец. Теперь S [ k ] = ‘о’ и расстояние от конца образца до символа ‘о’ в нем равно двум, значит, индекс k увеличиваем на два.
И опять не произошло совпадения образца со строкой. Теперь S [ k ] = ‘е’, такого символа в образце нет, поэтому мы можем сдвинуть образец сразу на его длину, т.е. увеличить индекс k на M.
Здесь S [ k ] = ’в’, расстояние от конца образца до символа ‘в’ равно единице, значит, индекс k увеличиваем на единицу.
Теперь S [ k ] = ’а’, такой символ в образце есть, но лишь в последней позиции, в остальной части образца его нет, поэтому увеличиваем индекс k на длину образца M.
Символа S [ k ] = ’ ’ в образце нет, увеличиваем индекс k на M.
|