Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
Восходящие распознаватели без возвратовСодержание книги
Поиск на нашем сайте Основная возможность улучшения алгоритма восходящего разбора также состоит в том, чтобы на каждом шаге работы однозначно принимать решение, что выполнять, сдвиг или свёртку, а также какие цепочку и правило выбирать для свёртки. В таком случае возвратов не выполняется, и количество проделанных шагов алгоритма имеет линейную зависимость от длины входной цепочки. Если алгоритм не заканчивается успешно, то входная цепочка не принимается, повторных итераций не производится. LR(k)-грамматики При моделировании восходящих распознавателей без возвратов может использоваться аналогичный подход, который был положен в основу определения LL(k)-грамматик. КС-грамматика обладает свойством LR(k), k³0, если на каждом шаге вывода для принятия однозначного решения по вопросу о выполняемом действии в алгоритме «сдвиг-свёртка» расширенному МПА достаточно знать содержимое верхней части стека и рассмотреть первые k символов от текущего положения считывающей головки автомата во входной цепочке символов. Грамматика называется LR(k)-грамматикой, если она обладает свойством LR(k). Обозначение грамматики LR(k) имеет смысл, аналогичный рассмотренной ранее аббревиатуре LL(k). Отличие состоит в символе R, который обозначает, что в результате работы распознавателя получается правосторонний вывод. Остальные символы имеют тот же смысл, что и в обозначении LL(k)-грамматики. В совокупности все LR(k)-грамматики для различных k³0 образуют класс LR-грамматик. Поскольку алгоритм восходящего распознавателя моделирует работу расширенного МПА, возможность k=0 не является абсурдом, т.к. в таком случае все равно автомат в процессе работы рассматривает цепочки символов на вершине стека и, следовательно, результат его работы зависит от входной цепочки (т.к. в стеке находится именно она). Класс LR-грамматик является более широким, чем класс LL. Это объясняется тем, что на каждом шаге работы расширенного МПА обрабатывается больше информации, чем при работе обычного МПА. Существует и строгое доказательство этого факта. Вообще, для каждого языка, заданного LL-грамматикой, может быть построена LR-грамматика, задающая тот же язык (при этом значения k в них не обязаны совпадать). Свойства LR(k)-грамматик. § Всякая LR(k)-грамматика для любого k³0 является однозначной. § Существует алгоритм проверки, является ли заданная КС-грамматика LR(k)-грамматикой для строго определённого числа k. § Класс LR-грамматик полностью совпадает с классом детерминированных КС-языков. Проблемы LR(k)-грамматик: § Не существует алгоритма, позволяющего проверить, является ли заданная КС-грамматика LR(k)-грамматикой для любого числа k. § Не существует алгоритма преобразования произвольной КС-грамматики к виду LR(k)-грамматики для некоторого k (либо доказывающего, что такое преобразование невозможно). Класс LR-грамматик удобен для построения распознавателей детерминированных КС-языков, следовательно, для распознавания языков программирования. Для формального определения LR(k)-свойства для КС-грамматик, нужно ввести ещё одно определение. Грамматика является пополненной, если её целевой символ не встречается нигде в правых частях правил. Для приведения произвольной КС-грамматики к такому виду необходимо к множеству правил добавить S¢®S, а S¢ сделать целевым символом. Формальное определение LR(k)-свойства. Если для произвольной КС-грамматики G в её пополненной грамматике G¢ для двух произвольных цепочек вывода из условий: 1. S¢ Þ* aAwÞ abw 2. S¢ Þ* gBxÞ aby 3. FIRST(k,w)= FIRST(k,y) следует, что aAy = gBx, т.е. a = g, A = B, x = y, то доказано, что грамматика G обладает LR(k)-свойством (так же, как и её пополненная грамматика G¢). Понятие пополненной грамматики введено для того, чтобы появление символа S¢ на вершине стека означало окончание работы алгоритма. Распознаватель для LR(k)-грамматик основан на специальной управляющей таблице T. Эта таблица состоит из двух частей, называемых «действия» и «переходы». По строкам таблицы распределены все цепочки символов на верхушке стека, которые могут приниматься во внимание в процессе работы распознавателя; по столбцам в части «действия»– все возможные части входной цепочки длины не более k символов, которые могут следовать за считывающей головкой в процессе выполнения разбора; в части «переходы» – все терминальные и нетерминальные символы, которые могут появляться на верхушке стека в процессе выполнения действий. Клетки управляющей таблицы в части «действия» содержат информацию о необходимых в каждой ситуации действиях, в частности: § «сдвиг», если требуется выполнение сдвига (переноса текущего символа из входной цепочки в стек); § «успех», если возможна свёртка к целевому символу грамматики S и разбор завершен; § целое число («свёртка»), если возможно выполнение свёртки (число обозначает номер правила грамматики, по которому должна выполняться свёртка); § «ошибка» – во всех других ситуациях. Клетки управляющей таблицы T в части «переходы» служат для определения номера строки таблицы, которая будет использоваться для выполнения действия на очередном шаге. Эти клетки содержат данные: § целое число – номер строки таблицы T; § «ошибка» – во всех других ситуациях. Для удобства работы используются два дополнительных символа начала и конца цепочки: ^н и ^к. Тогда в начальном состоянии работы распознавателя символ ^н находится на верхушке стека, а считывающая головка обозревает первый символ входной цепочки. В конечном состоянии в стеке должны находиться целевой символ и ^к, а считывающая головка должна обозревать символ ^к. Алгоритм работы распознавателя: Шаг 1 Занести в стек символ начала цепочки ^н и начальную (нулевую) строку управляющей таблицы T (её номер), в конец цепочки поместить символ ^к. Шаг 2 Прочитать с вершины стека строку управляющей таблицы T (её номер). Выбрать из неё часть «действие» в соответствии с аванцепочкой. Шаг 3 В соответствии с типом действия: – «сдвиг»: если это не ^к, то прочитать и запомнить как «новый символ» очередной символ входной цепочки, сдвинув считывающую головку вправо на 1 символ; иначе остановка с ошибкой; – «целое число, свёртка»: выбрать соответствующее числу правило (пусть это A ® b), убрать из стека 2×½b½ символов, запомнить A как «новый символ»; – «ошибка»: остановка с ошибкой; – «успех»: свернуть к S, если текущий символ ^к, то завершить с успехом, иначе завершить с ошибкой. Шаг 4 Прочитать с вершины стека строку таблицы T (её номер). Выбрать часть «переход» в соответствии с «новым символом». Шаг 5 Если «переход» содержит «ошибка», то остановка алгоритма с ошибкой. Иначе (если «переход» содержит номер) – в стек занести «новый символ» и строку таблицы (выбранный номер). Вернуться на шаг 2. Рассмотрим пример для LR(0)-грамматики. Пример. Рассмотрим грамматику G({a,b}, {S}, {S®aSS|b}, S). Данная грамматика определяет язык, в цепочках которого количество символов ‘a’ на один меньше, чем ‘b’, первый символ всегда ‘a’, в конце всегда пара ‘bb’. Исключение – минимальная цепочка ‘b’. Поскольку символ S входит в правую часть правил, необходимо преобразовать грамматику G в пополненную G¢. Правила P¢ перенумеруем. G¢({a,b},{S,S¢},P¢,S¢); P¢: (1) S¢®S; (2) S®aSS, (3) S®b.
Стек |
Действие |
Переход | ||||
| S | a | b | |||||
| 0 | ^н | сдвиг | 1 | 2 | 3 | ||
| 1 | S | успех, 1 | |||||
| 2 | a | сдвиг | 4 | 2 | 3 | ||
| 3 | b | свёртка, 3 | |||||
| 4 | aS | сдвиг | 5 | 2 | 3 | ||
| 5 | aSS | свёртка, 2 | |||||

Клетки таблицы в графе «переход», в которых должна содержаться «ошибка», оставлены пустыми и закрашены. Поскольку состояние распознавателя единственно, в записи конфигурации его можно опустить.
Стек лучше заполнять слева направо (для получения естественного порядка правил), поскольку выполняется правосторонний разбор.
Рассмотрим две цепочки: a1=¢aabbb¢; a2=¢aabb¢.
(aabbb^к,{^н,0}, e)├─(abbb^к,{^н,0; a,2}, e)├─ (bbb^к,{^н,0; a,2; a,2}, e) ├─ (bb^к, {^н,0; a,2; a,2; b,3 }, e)├─ (bb^к, {^н,0; a,2; a,2; S,4}, 3e)
├─ (b^к, {^н,0; a,2; a,2; S,4; b,3 }, 3)├─ (b^к, {^н,0; a,2; a,2; S,4; S,5 }, 33)
├─ (b^к, {^н,0; a,2; S,4}, 233)├─ (^к, {^н,0; a,2; S,4; b,3 }, 233)
├─ (^к, {^н,0; a,2; S,4; S,5 }, 3233)├─ (^к, {^н,0; S,1 }, 23233)
├─ (^к, {^н,0; S¢}, 123233) алгоритм завершён успешно, цепочка принята.
S¢Þ(1) SÞ(2) aSSÞ(3) aSbÞ(2) aaSSbÞ(3) aaSbbÞ(3) aabbb.
(aabb^к,{^н,0}, e)├─(abb^к,{^н,0; a,2}, e)├─ (bb^к,{^н,0; a,2; a,2}, e)
├─ (b^к, {^н,0; a,2; a,2; b,3 }, e)├─ (b^к, {^н,0; a,2; a,2; S,4}, 3e)
├─ (^к, {^н,0; a,2; a,2; S,4; b,3 }, 3)├─ (^к, {^н,0; a,2; a,2; S,4; S,5 }, 33)
├─ (^к, {^н,0; a,2; S,4}, 233)├─ алгоритм завершился с ошибкой.
На практике LR(k)-грамматики для k>1 не применяются: для любой LR(k)-грамматики можно построить эквивалентную ей LR(1)-грамматику, которая работает значительно эффективнее в силу меньших размеров управляющей таблицы.
Грамматики предшествования
Ещё один распространенный класс КС-грамматик, для которых возможно построить восходящий распознаватель без возвратов, представляют грамматики предшествования. Распознаватель для них строится также на основе алгоритма «сдвиг-свёртка».
Суть таких грамматик состоит в том, что для каждой упорядоченной пары символов в грамматике устанавливается некоторое отношение, называемое отношением предшествования. В процессе разбора входной цепочки распознаватель сравнивает текущий символ с одним из символов, находящихся на верхушке стека автомата. В процессе сравнения проверяется, какое из отношений предшествования существует между этими двумя символами, и в зависимости от найденного отношения выполняется либо сдвиг, либо свёртка. При отсутствии какого-либо отношения выдается сигнал об ошибке.
Таким образом, задача состоит в том, чтобы определить отношения предшествования между символами грамматики. В случае удачи грамматика может быть отнесена к одному из классов грамматик предшествования.
Существует несколько видов грамматик предшествования. Они различаются по тому, какие отношения предшествования в них определены и между какими типами символов (терминальными или нетерминальными) эти отношения могут быть установлены.
Выделяют следующие типы грамматик предшествования:
§ простого предшествования;
§ расширенного предшествования;
§ слабого предшествования;
§ операторного предшествования.
Наиболее распространены первый и последний типы грамматик.
Для примера рассмотрим грамматики операторного предшествования.
Грамматики, в которых все правила таковы, что в любой правой части никакие два нетерминала не являются смежными, и, следовательно, стоящий между ними терминал можно представить как оператор (хотя и не обязательно в арифметическом смысле), называются операторными грамматиками.
Пусть так же, как и в предыдущем разделе, кроме терминального алфавита VT имеются специальные символы {^н, ^к} (или {├, ┤}), которые ограничивают цепочку слева и справа соответственно.
Будем использовать следующие обозначения цепочек: bÎVNÈ{e} (т.е. нетерминал или пусто), a, g, dÎV* (V=VTÈVN). Определим отношения предшествования { @ ̇, < ×, ×> } на множестве VT È{^к, ^н}:
1. a @ b (a имеет такое же старшинство, как b), если A ® aabbg;
2. 
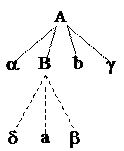 a < × b (a имеет меньшее старшинство, чем b), если A ® aaBg, B Þ+ bb d;
a < × b (a имеет меньшее старшинство, чем b), если A ® aaBg, B Þ+ bb d;
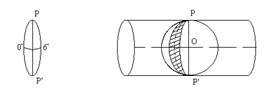
 Схематичное представление данного правила показано на первом рисунке.
Схематичное представление данного правила показано на первом рисунке.
3.  a ×> b (a имеет большее старшинство, чем b), если A ® aBbg, B Þ+ dab;
a ×> b (a имеет большее старшинство, чем b), если A ® aBbg, B Þ+ dab;
Схематичное представление правила показано на втором рисунке.
4. ^н < × a, если S Þ+ bad;
5. a × > ^к, если S Þ+ dab.
Если между любыми двумя операторами из VT È{^к, ^н} возможно не более одного такого отношения, то соответствующая операторная грамматика называется грамматикой операторного предшествования.
Пример.
Дана грамматика построения АВ с операциями сложения и умножения и скобками: G({x,+,*,(,)}, {S,T,R}, P, S), где правила P: S ® S+T (1)|T (2), T®T*R (3)|R (4), R®(S) (5)|x (6). Здесь вместо символа x может быть использовано любое целое число.
В соответствии с приведенными выше правилами определения отношений предшествования построим таблицу, в которую занесём отношения между всеми операторами данной грамматики:
| + | * | ( | ) | x | ^к | |
| ^н | <× | <× | <× | <× | ||
| + | ×> | <× | <× | ×> | <× | ×> |
| * | ×> | ×> | <× | ×> | <× | ×> |
| ( | <× | <× | <× | =̇ | <× | |
| ) | ×> | ×> | ×> | ×> | ||
| x | ×> | ×> | ×> | ×> |
Рассмотрим работу алгоритма разбора на базе грамматик ОП.
Цепочка a считается принятой, если за конечное число шагов произошел переход от начальной конфигурации к заключительной:
(^н a ^к, e,e)├─*(^к, ^н S,m) Þ stop(+).
Алгоритм:
1) Считывающая головка устанавливается на первый символ цепочки a1, в стек заносится ^н, i=1.
2) Верхний символ стека (или ближний к верху стека терминальный символ) сравнивается с ai.
3) Если отношение <× или = ̇, то выполняется сдвиг, i++, возврат на шаг 2.
4) Если отношение ×>, то выполняется свёртка. При этом если нет подходящего правила, то алгоритм заканчивается с ошибкой, иначе основа (символы, связанные отношением = ̇) удаляется из стека и сворачивается по найденному правилу. Далее возврат на шаг 2.
5) Если на шаге 2 отношение не найдено Þ завершение с ошибкой.
6) Если получена заключительная конфигурация – цепочка разобрана.
Дополнительные требования к правилам грамматики: (1) среди них не должно быть пустых правил; (2) не должно быть правил с одинаковыми правыми частями.
Вернёмся к примеру. S ® S+T | T, T®T*R | R, R® (S) | x.
Сначала устраним цепные правила. Получим: S ® S+T | T*R |(S) | x, T®T*R | (S) | x, R® (S) | x. Можно избавиться от лишних нетерминалов и оставить только один нетерминальный символ S. Правила примут вид:
S ® S+S (1)| S*S (2)| (S) (3) | x (4). Разбирается цепочка ^н x*(x+x) ^к.
[x*(x+x) ^к, ^н, e] ├─ { ^н < × x Þ сдвиг} [*(x+x) ^к, ^н x, e] ├─ {x ×> * Þ свёртка} [*(x+x) ^к, ^н S, 4e] ├─ { ^н < × * Þ сдвиг} [(x+x) ^к, ^н S*, 4] ├─ {* < × (Þ сдвиг} [x+x) ^к, ^н S*(, 4] ├─ {(< × x Þ сдвиг} [+x) ^к, ^н S*(x, 4] ├─ {x ×> + Þ свёртка} [+x) ^к, ^н S*(S, 44] ├─ {(< ×+ Þ сдвиг} [x) ^к, ^н S*(S+, 44] ├─ {+ < × x Þ сдвиг} [) ^к, ^н S*(S+x, 44] ├─ {x ×>) Þ свёртка} [) ^к, ^н S*(S+S, 444] ├─ {+ ×>) Þ свёртка} [) ^к, ^н S*(S, 1444] ├─ {(= ̇,) Þ сдвиг} [ ^к, ^н S*(S), 1444] ├─ {) ×> ^к Þ свёртка} [ ^к, ^н S*S, 21444] ├─ {* ×> ^к Þ свёртка} [ ^к, ^н S, 231444] ├─ stop (+).
Рассмотрим другой способ разбора. При вычислении значения выражения сначала выполняются операции с большим приоритетом.
В той же цепочке ^н x*(x+x) ^к подставим вместо символов x конкретные числа: ^н 3*(2+7) ^к – и запишем под ней знаки отношений:
| ^ н | 3 | * | ( | 2 | + | 7 | ) | ^ к | |||||||||
| < × | × > | < × | < × | × > | < × | × > | × > | ||||||||||
Рассмотрим процесс выполнения действий. Сначала будет выбрано из цепочки число 3 и сохранено в стеке. В результате останется:
| ^ н | * | ( | 2 | + | 7 | ) | ^ к | ||||||||
| < × | < × | < × | × > | < × | × > | × > | |||||||||
Теперь следует выбрать число 2 и сохранить его в стеке; останется:
| ^ н | * | ( | + | 7 | ) | ^ к | |||||||
| < × | < × | < × | < × | × > | × > | ||||||||
Теперь так же выбирается число 7 и сохраняется в стеке:
| ^ н | * | ( | + | ) | ^ к | ||||||
| < × | < × | < × | × > | × > | |||||||
| ^ н | * | ( | ) | ^ к | |||||
| < × | < × | = ̇ | × > | ||||||
Старшей операцией осталось сложение; его нужно применить к двум верхним элементам стека, результат остается в стеке, а символ операции «+» удаляем из цепочки. В итоге получится:
| ^ н | * | ^ к | |||
| < × | × > | ||||
Скобки имеют одинаковое старшинство и просто отбрасываются:
| ^ н | ^ к |
Производится умножение двух верхних элементов стека, результат остается там же, а знак операции удаляется:
Отношения предшествования между оставшимися символами отсутствуют, поэтому происходит остановка. Поскольку вся цепочка разобрана, результат её выполнения находится в стеке.
Вместо выполнения арифметических операций можно было бы породить код и только после этого уже вычислять значение выражения. Именно это бы и выполнил компилятор.
4.4.3. Контрольные вопросы
1. Какие существуют возможности сделать работу алгоритма нисходящего разбора с возвратами более эффективной?
2. Какие ограничения накладываются на правила грамматики для применимости метода рекурсивного спуска? Может ли в этих правилах использоваться левая или правая рекурсия? Почему?
3. Какими действиями можно привести правила грамматики к виду, необходимому для метода рекурсивного спуска?
4. В чём состоит основной недостаток метода рекурсивного спуска?
5. Какая грамматика обладает свойством LL(k)? Что означает это название? Может ли быть k=0?
6. В чём отличие вида правил грамматик класса LL(k) от грамматик, допускающих разбор по методу рекурсивного спуска?
7. Какой из видов рекурсии и почему запрещён в правилах LL-грамматик?
8. Какие дополнительные множества строятся для грамматик класса LL(k) и каково их назначение?
9. Как можно формально проверить, относится ли некоторая грамматика к классу LL(1)?
10. Для чего строится таблица в алгоритме нисходящего разбора для LL(1)-грамматики? Что заносится в эту таблицу? Может ли разбор выполняться без использования таблицы?
11. Что позволяет избежать возвратов в алгоритме восходящего разбора?
12. Какая грамматика обладает свойством LR(k)? Что означает это название? Может ли быть k=0?
13. Для чего нужна управляющая таблица в алгоритме разбора для LR-грамматик? Что заносится в эту таблицу? Может ли разбор входной цепочки выполняться без использования таблицы?
14. Для каких значений k обычно применяются на практике грамматики класса LR(k) и почему?
15. К какому классу распознавателей – восходящим или нисходящим – относятся распознаватели на базе грамматик предшествования?
16. Чем различаются грамматики предшествования?
17. Отношения между какими парами символов строятся в грамматиках операторного предшествования?
18. Какова трудоёмкость распознавателей на базе грамматик предшествования?
|
| Поделиться: |