Заглавная страница Избранные статьи Случайная статья Познавательные статьи Новые добавления Обратная связь FAQ Написать работу КАТЕГОРИИ: ТОП 10 на сайте Приготовление дезинфицирующих растворов различной концентрацииТехника нижней прямой подачи мяча. Франко-прусская война (причины и последствия) Организация работы процедурного кабинета Смысловое и механическое запоминание, их место и роль в усвоении знаний Коммуникативные барьеры и пути их преодоления Обработка изделий медицинского назначения многократного применения Образцы текста публицистического стиля Четыре типа изменения баланса Задачи с ответами для Всероссийской олимпиады по праву 
Мы поможем в написании ваших работ! ЗНАЕТЕ ЛИ ВЫ?
Влияние общества на человека
Приготовление дезинфицирующих растворов различной концентрации Практические работы по географии для 6 класса Организация работы процедурного кабинета Изменения в неживой природе осенью Уборка процедурного кабинета Сольфеджио. Все правила по сольфеджио Балочные системы. Определение реакций опор и моментов защемления |
В правоприменительной деятельностиСодержание книги Поиск на нашем сайте 1. Детерминированное событие определяется зависимостью «причина - следствие». Случайное событие ω характеризуется тем, что его исход непредсказуем. Под опытом понимается действие, результат которого неизвестен. Один или несколько опытов представляют эксперимент. 2. Элементарное событие ω – это возможный результат эксперимента (исход). Пространство элементарных событий Ω = {ω }, событие А = { ω1,…,ωn } Í Ω. Случайной величиной называется переменная, которая под воздействием случайных факторов может с определенными вероятностями принимать те или иные значения. 3. Классическое определение вероятности: p = m(A) / N, где m(A) – число благоприятных исходов, а N – общее число исходов.
4. Событие A =, случайная величина X(ω) = Закон распределения конечной случайной величины
Дискретная величина X принимает конечное число значений с определенными вероятностями, а непрерывная – бесконечное число значений и определяется тем, что существует функция f(x) (функция плотности), что
5. Функция распределения F(x) определяется соотношением
6. Если известно, что в результате эксперимента произошло некоторое событие B,p(B) > 0, и информация о нем учитывается при вычислении вероятности события А, то такая вероятность называется условной: p (A|B)= p (AB) / p(B). Свойства условной вероятности. § Если события A1 и А2 несовместны, то р(A1 + А2| В) = р(A1 | В) + р(А2|В). § Теорема умножения: р(АВ) = р(А | В)р(В) для независимых событий р(АВ) = р(А)р(В). 7. Формула полной вероятности. Если события H1, H2,..., Hn попарно несовместны и A Ì H1 + H2 +…+ Hn, то
8. Формула Байеса. Если события H1, H2,..., Hn попарно несовместны и событие A Ì H1 + H2 +…+ Hn, то при k = 1, 2,..., n справедлива формула апостериорной вероятности:
Таким образом, условная вероятность может быть использована как для уточнения вероятности с учетом вновь поступившей информации, так и для вычисления вероятности, что наблюдаемый эффект является следствием некоторой конкретной причины. Лекция 2 Вероятностные распределения, операции над случайными величинами, 1. Пусть заданы две конечные случайные величины:
Их суммой называется случайная величина X+Y, значениями которой являются возможные суммы xi + yj, i=1,2,…,m; j=1,2,…,n, с совместными вероятностями pij = p(X = xi , Y = yj). Произведением этих случайных величин называется случайная величина XY, значениями которой являются всевозможные произведения xi yj с теми же вероятностями pij. 2. Пусть X1, X2, …, Xn – независимые бернулиевы случайные величины:
Тогда их сумма есть биномиальная случайная величина:
3. Нормальное распределение случайной величины X (обозначение X ~ N (m,σ)) определяется плотностью распределения:
или функцией распределения:
Стандартным называется нормальное распределение N (0, 1). Функция Excel НОРМРАСП возвращает нормальную функцию распределения для указанного среднего и стандартного отклонения: НОРМРАСП (x; m; σ; интегральная), где § x – значение, для которого строится распределение, § m – среднее арифметическое распределения, § σ – стандартное отклонение распределения, § интегральная – логическое значение, определяющее форму функции. ФункцияExcel НОРМСТОБР возвращает обратное значение стандартного нормального распределения НОРМСТОБР (p), где p – вероятность, соответствующая нормальному распределению. 4. c2- распределение определяется следующим образом. Пусть ξ1, ξ2, …, ξk – независимые случайные величины, распределенные по стандартному нормальному закону: ξ1, ξ2, …, ξk ~ N(0, 1). Тогда говорят, что сумма квадратов этих случайных величин распределена по закону c 2 с k степенями свободы c2(k): c2(k) = ξ1 2 + ξ2 2 + …+ ξk 2 Функция ХИ2РАСП возвращает одностороннюю вероятность распределения c2 ХИ2РАСП (x; k), где § x – значение, для которого требуется вычислить распределение, § k – число степеней свободы распределения c2. Функция ХИ2ОБР возвращает значение обратное к односторонней вероятности распределения c2 ХИ2ОБР(p; k ), где § p – вероятность, связанная с распределением c2 , значение в диапазоне от 0 до 1, § k – число степеней свободы распределения c2. 5. Распределение Стьюдента (t -распределение) с k -степенями свободы определяется формулой
Функция СТЬЮДРАСП возвращает вероятность для t -распределения Стьюдента СТЬЮДРАСП (x; k; b ), где § x – численное значение, для которого требуется вычислить распределение, § k – количество степеней свободы, § b = 1 дает одностороннее распределение, § b = 2 дает двухстороннее распределение, Функция СТЬЮДРАСПОБР возвращает обратное распределение Стьюдента СТЬЮДРАСПОБР(p; k), где § p – вероятность, связанная с двуххвостовым t-распределением Стьюдента § k – положительное целое число степеней свободы, характеризующее распределение. Лекция 3 Первичная обработка данных. Выборочные характеристики и 1. При рассмотрении выборки X n = { х1, х2,..., хn } предполагается, что соответствующаягенеральная совокупность характеризуется функцией распределения F(x). Функция распределения F n(x) эмпирической случайной величины
определяется как
2. Выборочное (эмпирическое) среднее и выборочная дисперсия определяются формулами:
3. Первичная обработка данных. Частотный анализ. Если среди чисел { х1, х2,..., хn } имеется k различных (k < n) чисел z1, z2, …, zk ичисло zi встречается ni раз i = 1, 2,..., k, то ni называется частотой элемента zi, а fi = ni /n – относительной частотой. Последовательность Z = { (zi, ni) } называется, в таком случае, статистическим рядом. Если z1, z2, …, zk упорядочены по возрастанию, то Ni = n1 + n2 +... + ni называютсянакопленной частотой, а Fi = f1 + f2 +... + fi – накопленной относительной частотой. 4. Квантили. Медиана. Мода § 90-% выборочная квантиль – это значение, левее которого расположены 90% значений вариационного ряда; § выборочная медиана – это середина вариационного ряда; § выборочная мода – это наиболее вероятное, т.е. чаще всего встречающееся, значение в выборке. 5. Назовем уровнем значимости некоторое малое число α (обычно α = 0.01, 0.05, 0.1). Тогда интервальная оценка параметра θ представляет интервал (θ1, θ2) = [θ1(x1, …, xn), θ2(x1, …, xn), содержащий параметр θ. Его границе определяются по выборке x1, …, xn и p(θ1 < θ < θ2) = 1 – α. Таким образом, в интервал ( θ1, θ2 ) истинное значение параметра θ попадаетс относительно большой вероятностью 1 – α. Интервал ( θ1, θ2 ) называется доверительным интервалом для параметра θ с доверительной вероятностью 1 – α. Лекция 4 Статистические гипотезы и схема их проверки в процессе производства 1. Исследования в юридической практике часто связаны с выдвижением и проверкой гипотез о параметрах генеральной совокупности X. Эти утверждения основываются на опыте, предположениях и интуиции. Проверка гипотез представляет статистическую процедуру основанную на использовании выборочных данных X n = { x1, х2,..., хn }. Она представляет процесс принятия решения о том, чтобы принять или отвергнуть рассматриваемую гипотезу. 2. Обычно проверяемую гипотезу обозначают H0, а альтернативную ей гипотезу – H1. При проверке гипотез возможны следующие ситуации: § H0 верна и не отвергается; § H0 верна но отвергается; такая ситуация называется ошибкой I рода. § H0 неверна и отвергается; § H0 неверна, но не отвергается; такая ситуация называется ошибкой II рода. 3. Общая схема проверки гипотез представляет следующую процедуру: § сформулировать Н0 и Н1 и задать случайную величину Z - статистику критерия (значимости), которую можно вычислить по выборке; § задать уровень значимости α, который определяет критическую область V равенством p(Z Î V) = α; условия задания области V представляют критерий, а дополнение к критической области (R\V) называется областью принятия решения; § при вычислении вероятности р по выборке, возможны два случая: a) если p £ α, то данные выборки противоречат гипотезе Н0(Z Î V), что означает, что гипотеза H0 отклоняется(т.е. принимается H1); b) в противном случае, когда p > α (Zs Î R\V), данные подтверждают Н0, которая и принимается; 4. Если мы знаем доверительный интервал, для уровня значимости α, то критическая область V может рассматриваться как дополнение к доверительному интервалу. Например, для гипотезы H0: т = т0, если
то критическая область V задается неравенствами
Лекция 5
|
|||||||||||
|
|
Последнее изменение этой страницы: 2016-09-20; просмотров: 484; Нарушение авторского права страницы; Мы поможем в написании вашей работы! infopedia.su Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав. Обратная связь - 216.73.217.64 (0.009 с.) |





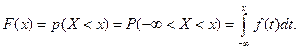







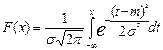
 ~ N(0, 1).
~ N(0, 1).
 .
.

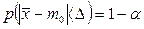 ,
, .
.